Cybersecurity incidents can happen to anyone, at any time. Whether it's a data breach, malware attack, or other security event, having a plan in place can mean the difference between swift resolution and costly downtime.
That's why you need an Incident Response Plan (IRP) to help respond quickly and effectively to security incidents. While no IRP can make your firm bulletproof, a good one will protect your organization's assets and ensure business continuity. In fact, the breach cost savings were USD 2.66 million for organizations with an Incident Response (IR) team and regularly tested IR plan compared to no team or testing.
To help your organization achieve similar savings and protection, this article outlines essential steps to build an effective incident response plan.
What is an Incident Response Plan (IRP)?
An IRP is a set of guidelines that outline how an organization should respond to a cybersecurity incident, such as a data breach, ransomware attack, or other security event.
Knowing what happens in each phase of an IRP, defining clear roles and responsibilities, setting up a communication plan, and setting key performance indicators (KPIs) are all important components of a successful incident response plan.
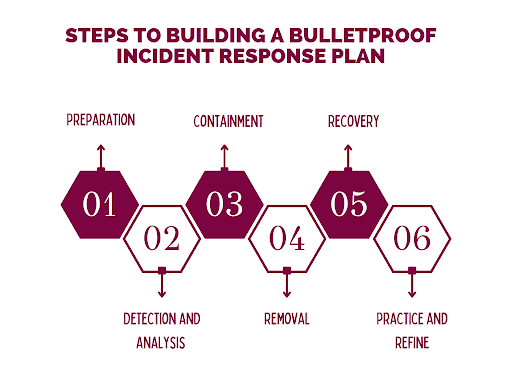
Step 1: Preparation
Preparation is like building a strong foundation for your IRP. This phase ensures that your team is equipped to handle any cyber threats or data breaches. How can you achieve this?
- Start by drafting a clear incident response policy that outlines your approach.
- Set up an incident response team consisting of IT, management, and communications.
- Make sure each member understands their role, responsibilities, and the importance of a unified response.
- Implement technologies such as SIEM, EDR, event monitoring, firewalls, etc
This step is an ongoing process so it's necessary to continue to review and refine your policy, and train your team to stay ahead of threats.
Step 2: Detection and Analysis
To detect incidents, you need to know what normal looks like. This means establishing a baseline of typical system behavior, network traffic, and user activity. With this baseline, you can identify unusual patterns or anomalies that may indicate a security incident. To achieve this;
- Monitor systems using SIEM tools, intrusion detection, firewalls, etc
- Identify anomalies that deviate from the baseline.
- Analyze anomalies to determine if they indicate a security incident.
By detecting incidents quickly, you can substantially reduce the impact of a breach. In fact, an IBM report found that internal detection can save nearly $1 million in breach costs, and businesses that detect breaches quickly avoid an average delay of 277 days, which can have serious implications.
Step 3: Containment
This step involves swift and careful action to prevent further harm. As noted in NIST SP 800-61, containment involves isolating affected systems to prevent further damage. Containment strategies include:
- Isolating affected systems to prevent lateral movement and stop the breach from spreading
- Disconnecting compromised devices from the network and blocking malicious IP addresses
- Backing up important data to preserve evidence and ensure integrity
- Applying temporary fixes to vulnerable areas to mitigate the threat
- Developing a long-term plan to fully contain and understand the threat, balancing containment with the risk of further damage.
Step 4: Removal
After containing the attack, you need to remove the root cause. This entails;
- Identifying the exact cause of the breach to understand what happened
- Cleaning up; removing malware, fixing vulnerabilities, and patching weaknesses
- Updating security policies, software, and tools to prevent future incidents
- Reinforcing network boundaries with enhanced firewalls and segmentation
Step 5: Recovery
After implementing all the steps above, it’s time to restore your systems and data to their normal state. You can do this by:
- Using your baseline data (from Step 2) to guide the recovery process
- Restoring systems, databases, and applications to their normal functioning state
Step 6: Root Cause Analysis
After your systems are restored, it's crucial to understand the underlying cause of the incident. This step involves a thorough investigation to determine what triggered the issue in the first place. You can do this by:
- Reviewing logs, alerts, and other relevant data to identify the source of the problem.
- Analyzing the sequence of events that led to the incident.
- Documenting findings and developing recommendations to prevent similar incidents in the future.
Step 7: Practice and Refine
Regular practice and simulation are crucial to ensure your team is prepared for real-world incidents. Follow these steps:
- Rotate scenarios: Test your team's response to different incidents (phishing, data center outages, ransomware, DoS attacks).
- Conduct tabletop exercises: Simulate incident response exercises to test decision-making and communication.
- Debrief and refine: Hold debriefing sessions to identify areas for improvement, refine processes, and update plans.
Building a solid IRP is crucial for protecting your organization against cybersecurity threats. Following these steps will ensure that your team is prepared to handle any incident effectively. Regular training, continuous monitoring, and practice drills are also essential to keeping your incident response plan sharp and ready for real-world challenges.
Stay informed and up-to-date on the latest cybersecurity insights and best practices - subscribe to the Cyberkach blog for more resources.